
Last updated: July 2, 2026
Technical discovery is the work founders do before development to find the expensive unknowns in an MVP. It pressure-tests architecture, integrations, data, security, AI feasibility, QA, launch needs, and timeline assumptions before a team starts turning a rough product idea into production code.
The practical goal is not to make the MVP bigger. It is to make version one smaller, clearer, and less fragile. A founder should leave technical discovery knowing what must be built now, what can wait, which assumptions still need proof, and which technical choices could burn budget if they are guessed too early. A broader product discovery sprint should resolve the customer, value, usability, and business risks around that technical work.
That matters because early estimates are fragile. McKinsey and the University of Oxford found that large IT projects ran 45% over budget and 7% over time on average, while delivering less value than expected. A startup MVP is smaller than a major enterprise program, but the same pattern shows up when teams price visible features and miss hidden risk.
If you are still shaping version one, pair this guide with Hapy’s MVP Development page and the deeper guide to custom software development cost by risk. If the architecture itself is the open question, Hapy’s web application architecture guide is the natural next read.
What technical discovery should answer before an MVP build
A technical discovery phase should answer one founder-level question: what could make this MVP more expensive, slower, riskier, or less useful than the feature list suggests?
That answer usually sits across ten areas:
| Discovery area | What to decide | Budget risk if skipped |
|---|---|---|
| Product boundary | The first user, workflow, outcome, and non-goals | Version one becomes a vague platform instead of a focused test |
| Architecture | App structure, backend shape, hosting, environments, and scale assumptions | The team overbuilds for imaginary scale or underbuilds a foundation that soon needs replacing |
| Integrations | APIs, auth, webhooks, rate limits, retries, and failure handling | ”Simple integrations” turn into weeks of edge cases and support work |
| Data | Data model, tenancy, imports, analytics, retention, and ownership | Reporting breaks, migrations get messy, and privacy decisions arrive late |
| Security | Access control, secrets, encryption, logs, permissions, and vendor risk | A launchable demo becomes unsuitable for real users or enterprise review |
| Compliance | HIPAA, PCI DSS, GDPR, SOC 2, FDA, KYC, AML, or customer security needs | The MVP must be rebuilt before it can sell into the target market |
| AI feasibility | Model choice, retrieval, evaluation, cost controls, fallback paths, and human review | A slick demo becomes too expensive or unreliable in production |
| QA | Acceptance criteria, test coverage, regression checks, device coverage, and UAT | Early users lose trust because the core loop is unstable |
| Launch | Deployment, monitoring, rollback, support, analytics, and incident ownership | The team ships without knowing whether the product is working |
| Budget and timeline | Build range, contingency, sequence, and tradeoffs | The founder compares quotes that are not pricing the same risk |
This is why a software discovery phase should sit between product strategy and development. It gives founders a technical map of what they are buying, what they are deferring, and where a cheap first version could become expensive later.
Architecture discovery: choose the simplest system that can carry the risk
Architecture discovery should not start with a favorite stack. It should start with the product’s real constraints.
For many startup MVPs, the right answer is a simple web application: managed auth, a conventional backend, a managed database, straightforward hosting, and one or two reliable integrations. That can be enough when the goal is to prove demand, learn from users, and avoid unnecessary engineering ceremony.
But simple does not mean careless. A marketplace that needs seller payouts, a healthcare workflow that touches patient data, an AI assistant that can change business records, or a B2B tool syncing with a CRM all carry different architecture risk. The discovery question is: which parts must be production-grade from day one because failure would invalidate the MVP?
Use this rule of thumb:
| MVP condition | Architecture posture |
|---|---|
| The product tests demand with low operational risk | Keep the stack boring, managed, and fast to change |
| The product handles payments, permissions, or sensitive data | Design the data model, audit trail, and access control before screens |
| The product depends on external systems | Build retries, queues, sandbox tests, and clear ownership of failed syncs |
| The product includes AI actions that affect users or records | Add evaluation, approval, rollback, and usage controls before launch |
| The product may need enterprise buyers soon | Keep security, tenancy, observability, and documentation credible early |
The expensive mistake is treating every MVP shortcut as harmless. Some shortcuts are fine: manual admin operations, delayed automation, a limited dashboard, or concierge support. Other shortcuts create rebuild pressure: weak tenancy, unclear permissions, no audit trail, hard-coded business rules, or a payment flow that cannot survive disputes.
Integrations: the first successful API call is not the hard part
Integration risk is usually underestimated because the demo path looks easy. The team connects an API, moves test data, and sees a happy-path response. The cost appears later, when the external system is slow, rate-limited, inconsistent, undocumented, or used differently by real customers.
Discovery should inspect five integration details before development:
- Authentication and authorization: How are tokens created, refreshed, scoped, and revoked?
- Data contracts: What fields are required, optional, nullable, transformed, or owned by another system?
- Failure modes: What happens when the API is unavailable, returns a partial response, or accepts one record and rejects the next?
- Rate limits and sequencing: Can the MVP process realistic user volume without hitting API limits?
- Operational visibility: Who sees sync failures, retries, duplicate records, and manual exceptions?
Marketplace payments are a good example. Stripe’s Connect documentation separates patterns such as destination charges, where the platform creates a charge and transfers funds to a connected account, from separate charges and transfers, where the platform creates charges and transfers later. Those are not cosmetic implementation choices. They affect seller onboarding, payout timing, dispute handling, platform balance, reporting, and sometimes regulatory exposure.
For a marketplace MVP, the discovery output should not just say “Stripe integration.” It should say which Connect model will be used, how seller verification works, what happens during a chargeback, whether payouts are manual or automatic, and what operational admin screens are needed for launch.
CRM integrations create a different version of the same problem. HubSpot’s Salesforce documentation notes that upgraded company sync can use mapped field values for deduplication, support association sync, and allow sync direction choices in some cases. It also warns that upgrading may temporarily increase Salesforce API usage. That is exactly the kind of detail a technical discovery sprint should catch before the founder promises “two-way CRM sync” as if it were one checkbox.
Data discovery: budget follows the data model
Data decisions decide how expensive the MVP becomes after launch. A product can look simple in Figma and still carry a difficult data problem underneath.
Discovery should define:
- Core entities: users, accounts, vendors, listings, orders, messages, events, files, or records.
- Ownership: which system is the source of truth for each field.
- Tenancy: whether customers, teams, locations, or vendors need isolated data.
- Permissions: who can view, edit, approve, export, delete, or recover each object.
- Analytics: what events must be tracked to know whether the MVP is working.
- Retention: what data must be kept, deleted, anonymized, or auditable.
- Migration: whether old data must be imported, cleaned, mapped, or reconciled.
This is where founders often save money by narrowing the first release. A CRM-connected MVP may not need every object synchronized on day one. A marketplace may not need advanced seller analytics. A compliance-heavy workflow may not need every automation before it has a reliable audit trail.
The budget question is: which data must be right for the MVP to produce useful evidence? Everything else is a candidate for build later.
Security and compliance: do not retrofit the rules that decide whether you can sell
Security discovery protects the founder from a painful pattern: shipping a product that works, then discovering it cannot be used by the target customer.
For healthcare software, the HHS summary of the HIPAA Security Rule explains that regulated entities must use administrative, physical, and technical safeguards for electronic protected health information. For payment products, PCI SSC describes PCI DSS as technical and operational requirements for entities that store, process, or transmit cardholder data. For AI-enabled medical device software, FDA guidance on Predetermined Change Control Plans describes how planned AI modifications may be handled inside marketing submissions.
Not every startup needs all of that. But every startup needs to know whether it is entering a regulated workflow before it builds the wrong foundation.
Compliance-heavy MVPs should answer these questions during discovery:
| Question | Founder implication |
|---|---|
| Are we touching regulated data or only metadata? | Changes database design, vendor choices, logging, and support process |
| Can a hosted payment or tokenized flow reduce PCI scope? | May avoid unnecessary card-data handling and audit burden |
| Do buyers require SOC 2 evidence before pilots? | May require logging, access reviews, vendor review, and policy work earlier |
| Are we making clinical, financial, or legal recommendations? | May require human review, disclaimers, documentation, and legal review |
| What must be auditable from day one? | Audit logs are much cheaper to design early than reconstruct later |
Security also matters for AI. IBM’s 2025 Cost of a Data Breach report highlights an AI oversight gap, including that 63% of organizations lacked AI governance policies and that the global average breach cost was $4.4 million. A startup should not copy enterprise security theater, but it should avoid putting sensitive customer data into unmanaged AI workflows without access controls, logging, and clear data handling rules.
AI feasibility: test reliability, human review, and token economics early
An AI assistant MVP should not be scoped as “chatbot plus dashboard.” The technical discovery work should identify what the assistant is allowed to know, what it is allowed to do, how output quality will be measured, when a human must approve, and how usage cost will be controlled.
For a low-risk assistant, a simple retrieval-augmented generation flow may be enough: ingest a small knowledge base, retrieve relevant documents, generate an answer, cite sources, and collect feedback. For a higher-risk workflow, such as an assistant that drafts customer responses, updates CRM records, triages compliance exceptions, or recommends payments, the team needs stronger controls.
Human-in-the-loop architecture is one of those controls. LangGraph’s documentation on interrupts describes how graph execution can pause, save state through persistence, and wait for external input before continuing. Microsoft Agent Framework documentation describes a similar request-and-response pattern for workflows that need human operator input before proceeding.
For founders, the budget point is simple: AI cost is not only model calls. It includes:
- data preparation and permissions;
- evaluation sets and quality review;
- prompt and retrieval testing;
- tool-use limits and approval rules;
- token and model cost monitoring;
- fallback paths when confidence is low;
- support review for harmful, wrong, or incomplete outputs.
If an AI assistant needs human review, design that review as part of the MVP. Do not pretend the human is temporary unless the discovery sprint has shown what quality threshold automation must hit before review can be reduced.
QA and launch discovery: define the quality bar before the first bug report
QA is not a cleanup phase at the end. It is part of technical discovery because different MVPs need different quality bars.
A clickable investor demo can tolerate rough edges. A pilot used by five internal operators needs reliable core flows and fast support. A payment, healthcare, or customer-facing workflow needs stronger release discipline because the cost of losing trust is high.
The discovery phase should define:
| QA or launch item | What should be decided |
|---|---|
| Acceptance criteria | What must be true for each core workflow to count as done |
| Test depth | Unit, integration, end-to-end, device, browser, accessibility, and security checks |
| Staging data | Whether realistic test data, sandbox integrations, or anonymized customer data are needed |
| Release plan | Who approves launch, how rollback works, and what can be feature-flagged |
| Monitoring | Errors, performance, failed jobs, API health, uptime, and user behavior |
| Support loop | How bugs are reported, triaged, fixed, and communicated during pilot use |
This is where a founder can make useful budget tradeoffs. Maybe the MVP does not need a full admin analytics suite, but it does need error monitoring, payment failure alerts, and a manual operations queue. Maybe the first CRM sync does not need every field, but it does need a visible sync log and a retry button.
Build-now/build-later matrix for technical discovery
The build-now/build-later decision should compare business learning value against technical complexity. The goal is to spend version-one budget on proof, not infrastructure theater.
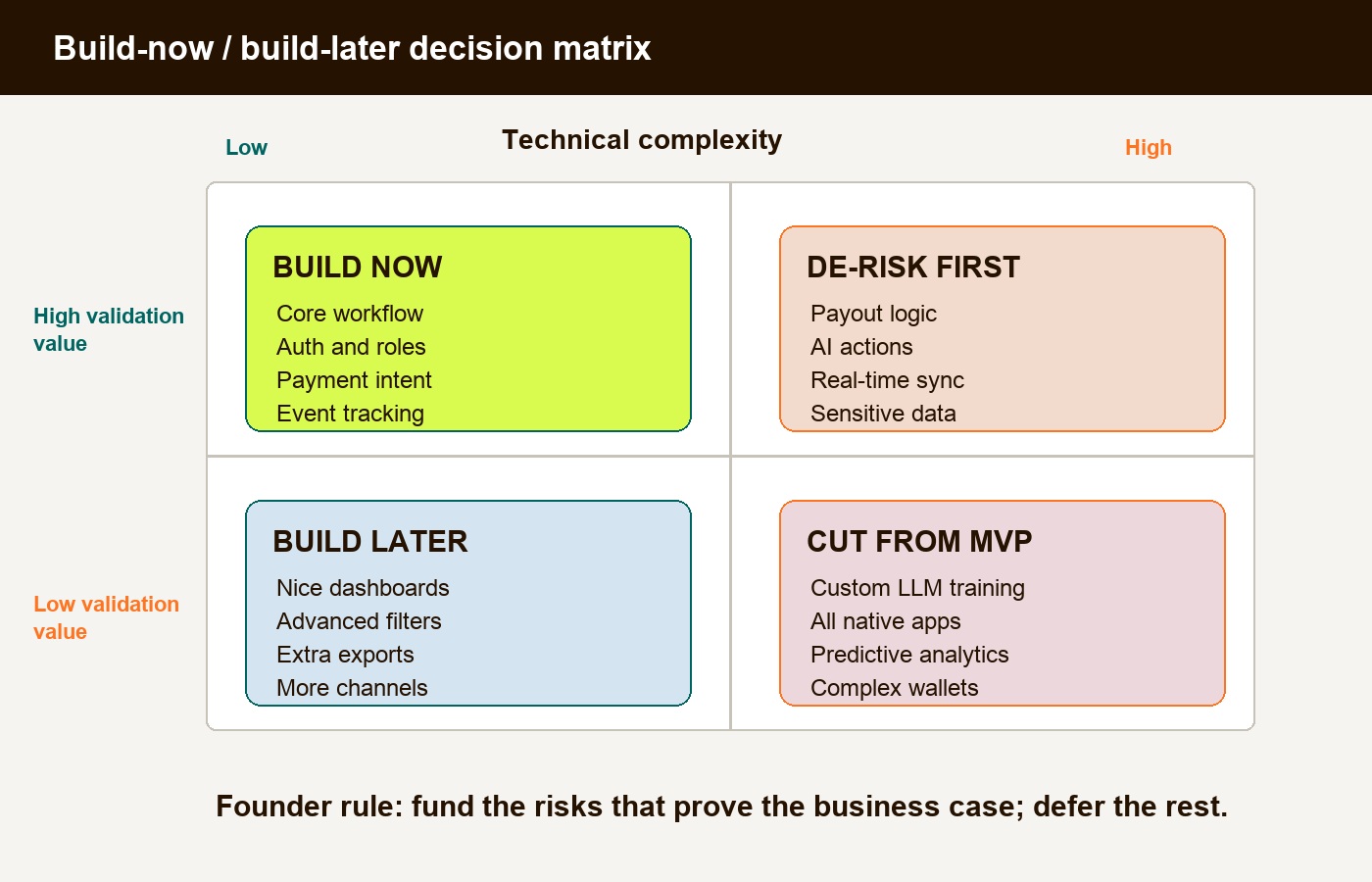
| Low technical complexity | High technical complexity | |
|---|---|---|
| High validation value | Build now. Core workflow, user auth, basic roles, payment intent, simple admin review, event tracking. | De-risk first. Marketplace payouts, regulated data handling, AI actions, real-time sync, multi-tenant permissions. |
| Low validation value | Build later. Nice dashboards, advanced filters, automated exports, extra notification channels. | Cut from MVP. Custom model training, complex multi-currency wallets, native apps for every platform, advanced predictive analytics. |
For founders, this matrix is a budget guardrail. If a feature is high complexity and low validation value, it is probably not version one. If a feature is high complexity and high validation value, it may still belong in the MVP, but it should be spiked, simplified, delegated to a managed service, or isolated behind a narrower launch path.
Technical feasibility scoring table
Use a lightweight feasibility score to compare MVP components. Score each item from 1 to 5 for technical complexity, integration effort, and operational risk. Multiply the three scores. Anything above 45 deserves simplification, a technical spike, or a build-later decision before the team commits to a timeline.
| MVP component | Complexity | Integration effort | Operational risk | Score | Discovery recommendation |
|---|---|---|---|---|---|
| Marketplace split payouts | 4 | 4 | 5 | 80 | Use a managed marketplace payment pattern first; avoid custom escrow unless it is the core thesis |
| HIPAA-grade audit logging | 3 | 2 | 5 | 30 | Design access logs, retention, and review early; keep the first workflow narrow |
| AI assistant with human review | 4 | 3 | 4 | 48 | Build approval checkpoints, evaluation, and cost limits before expanding actions |
| Two-way CRM sync | 4 | 4 | 3 | 48 | Start with a limited field map, source-of-truth rules, retries, and a sync log |
| OAuth and SSO foundation | 2 | 2 | 3 | 12 | Use managed auth unless custom identity is part of the product advantage |
The number is not magic. It is a forcing function. It makes the team explain why one feature is more dangerous than another and where the founder should spend discovery time.
Technical risk register for a startup MVP
A risk register should be short enough to use. Each risk needs an owner, a prevention plan, a reduction plan, and a contingency plan. If the team cannot name those four things, the risk is not understood yet.
| Risk | Category | Severity | Owner | Prevention | Reduction | Contingency |
|---|---|---|---|---|---|---|
| Seller payouts fail because the payment model does not match settlement timing | Integration | 15 | Lead engineer | Choose the Connect model during discovery and test payout paths in sandbox | Add payout status, manual review, and alerts | Pause automated payouts and move to manual operations until fixed |
| CRM sync creates duplicate or partial records | Data integration | 16 | Integration lead | Define source-of-truth rules and field ownership | Add dedupe, idempotency, queues, retries, and sync logs | Disable two-way sync and fall back to one-way export |
| AI assistant takes an action without human approval | AI and product risk | 20 | Product owner | Define action classes that require approval | Add checkpoints, confidence thresholds, and audit logs | Roll back action, notify operator, and disable autonomous mode |
| Regulated data is stored without the right access control or audit trail | Compliance | 20 | Security owner | Classify data and design permissions before build | Log access and separate sensitive tables from general metadata | Freeze affected workflow and remediate before broader launch |
| QA starts too late and the pilot breaks on the core workflow | Delivery | 12 | Delivery lead | Define acceptance criteria before development | Add regression checks around the core path | Delay launch or reduce scope to the stable workflow |
The risk register is not a scare document. It is a budget document. It tells the founder which risks deserve money now and which can be accepted because they are unlikely, reversible, or not tied to the first proof point.
Discovery output checklist
By the end of a technical discovery sprint, a founder should have enough evidence to compare build proposals honestly. The output does not need to be a giant requirements binder. It should be a compact plan that a senior product and engineering team can execute from.
| Output | What it should include |
|---|---|
| MVP scope | First user, first workflow, core jobs, non-goals, and launch definition |
| Architecture notes | App structure, hosting, database, auth, environments, scalability assumptions |
| Data model | Core entities, tenancy, permissions, analytics events, retention, and migration needs |
| Integration plan | APIs, auth method, webhooks, rate limits, sandbox access, retries, and failure handling |
| AI feasibility notes | Model approach, data sources, evaluation plan, human review, usage caps, fallback paths |
| Security and compliance notes | Data classification, access controls, audit logs, vendor review, regulatory questions |
| QA plan | Acceptance criteria, test types, device/browser coverage, staging data, UAT owner |
| Launch plan | Deployment path, monitoring, rollback, support loop, analytics, and pilot criteria |
| Risk register | Highest-priority risks, owners, prevention, reduction, and contingency plans |
| Build estimate | Timeline, budget range, assumptions, exclusions, contingency, and build-later list |
If the discovery output is only a feature list, it is incomplete. If it gives the founder clearer tradeoffs, it has done its job.
Timeline and cost signals for a technical discovery sprint
A technical discovery sprint can be short, but it should be long enough to test the risky assumptions.
| MVP risk level | Practical discovery timeline | Cost signal |
|---|---|---|
| Low-risk validation MVP | 1-2 weeks | Scope, workflow, simple architecture, launch checklist |
| Standard SaaS or workflow MVP | 2-4 weeks | Roles, data model, integrations, QA plan, build estimate |
| Marketplace, AI, CRM-heavy, fintech, or healthcare MVP | 3-6 weeks | Technical spikes, compliance review, sandbox testing, risk register |
The discovery budget should feel small compared with the cost of rebuilding the wrong thing. If the build budget is tight, discovery becomes more important, not less, because the founder has less room for rework.
Cost signals that justify deeper discovery include:
- more than one external system of record;
- payments, payouts, refunds, or disputes;
- regulated or sensitive customer data;
- AI that writes, decides, or triggers actions;
- multi-tenant permissions;
- migration from an existing tool;
- enterprise buyer security review;
- real-time sync or notifications;
- a launch date tied to fundraising, pilots, or sales commitments.
If none of those are present, keep discovery lean. If several are present, do not let a low-confidence estimate pretend the risk is gone.
The founder takeaway
Technical discovery is not a delay before the real work. It is how founders protect the real work from version-one mistakes that burn runway: the wrong architecture, brittle integrations, unplanned compliance, weak data models, uncontrolled AI costs, vague QA, and launch plans that only exist after something breaks.
The best MVP technical planning is specific enough to guide engineers and plain enough to help founders make tradeoffs. Build the smallest version that can prove the business case. De-risk the technical pieces that could make that version fail. Push everything else into build later.
For related planning, read Hapy’s guides to software development risks, web application architecture, and MVP development cost. If version one is already starting to feel technically expensive, start with discovery before you start with code.


