
Technical debt cost in 2026 is the hidden tax paid when software teams spend their best hours maintaining past shortcuts instead of creating new business value. It shows up as slower releases, fragile integrations, higher QA spend, security exposure, developer churn, and AI initiatives that look productive until the rework bill arrives.
For CEOs, founders, and CTOs, the practical question is no longer “Should we refactor?” The better question is: “How much of our engineering budget is still creating assets, and how much is servicing old debt?”
What is the technical debt cost in 2026?
Technical debt cost is the total business cost of carrying software shortcuts. It includes remediation work, extra testing, delayed features, infrastructure waste, incident response, and the opportunity cost of senior engineers spending time on low-leverage maintenance.
The clearest macro benchmark still comes from the Consortium for Information & Software Quality. Its latest major US report estimated the cost of poor software quality at $2.41 trillion and accumulated technical debt at about $1.52 trillion. Those numbers were published in 2022, but the 2026 operating environment has made them more relevant, not less: codebases are larger, AI-assisted code is spreading, and modernization budgets are competing with platform, data, and security work.
IBM’s 2026 technical debt analysis makes the business case sharper. Enterprises that fully account for the cost of addressing debt in AI business cases project 29% higher ROI than those that do not, while ignoring debt can cut expected returns by 18% to 29%.
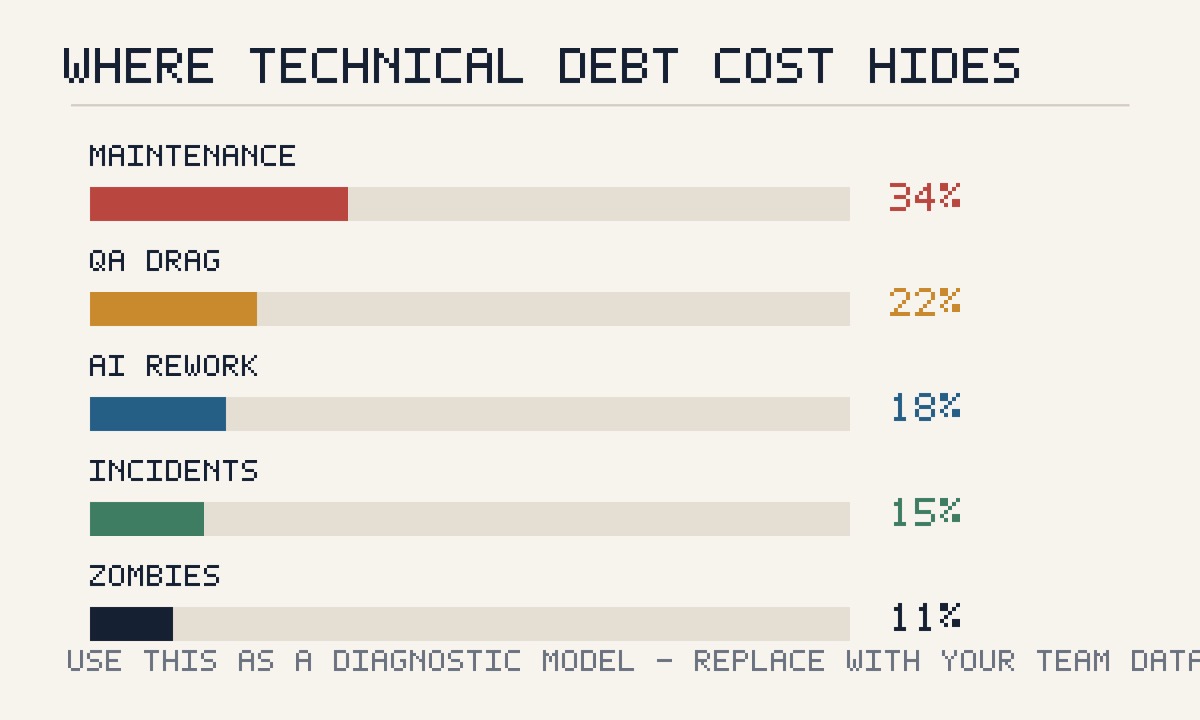
| Cost signal | What it means for the business | What leaders should measure |
|---|---|---|
| Maintenance share | Salary dollars going to fixes, support, and workaround work | Percent of sprint capacity spent on debt |
| Defect escape cost | Bugs found after release cost more to repair and explain | Escaped defects, incident hours, hotfix rate |
| Modernization drag | Old systems slow integrations and AI adoption | Cycle time around high-churn modules |
| Zombie features | Low-value features still consume QA, infra, and support | Feature usage vs maintenance cost |
| AI code rework | Fast output creates review, security, and consistency costs | AI-authored change failure rate |
Why technical debt hides inside normal engineering budgets
Technical debt is difficult to manage because it rarely arrives as a separate invoice. It is buried inside sprint tickets, bug triage, cloud bills, regression testing, deployment delays, and “simple” changes that take three weeks because the system has become brittle.
One widely cited developer productivity benchmark found that developers spend 13.4 hours per week dealing with bad code. That is about one-third of a standard work week. For a 50-person engineering team with a fully loaded cost of $100,000 per developer, that rough benchmark implies about $1.65 million per year of salary capacity tied up in rework and maintenance.
The exact number will differ by company, but the pattern is reliable. If engineers routinely spend Monday fixing regressions, Tuesday unpicking fragile dependencies, and Wednesday stabilizing a release that should have gone out last week, the roadmap is being taxed before product planning even begins.
This is why technical debt should be discussed in business language. “We need to clean up the codebase” is easy to postpone. “Thirty-two percent of engineering capacity is unavailable for roadmap work” is harder to ignore. The conversation also depends on software development team structure, because unclear ownership makes debt harder to measure and repay.
AI has changed the debt equation
AI coding tools can reduce technical debt when they help teams understand legacy code, generate test scaffolds, draft migration plans, and automate repetitive refactors. The risk is that the same tools can also produce more code faster than the organization can review, govern, or maintain.
Researchers studying GenAI-Induced Self-Admitted Technical Debt, or GIST, describe cases where developers explicitly note uncertainty about AI-generated code but still move it toward the codebase. The paper frames GIST as a recurring pattern in which AI output is useful enough to keep but unclear enough to become future maintenance debt.
A separate large-scale 2026 study of AI-authored commits found 484,606 distinct issues across verified AI-generated changes. Code smells accounted for 89.1% of those issues, more than 15% of commits from every major assistant introduced at least one issue, and 24.2% of tracked AI-introduced issues still survived in the latest repository revision. That is the new debt profile of AI-assisted development: not always broken, but often harder to maintain later. See the arXiv study on AI-generated code in the wild.
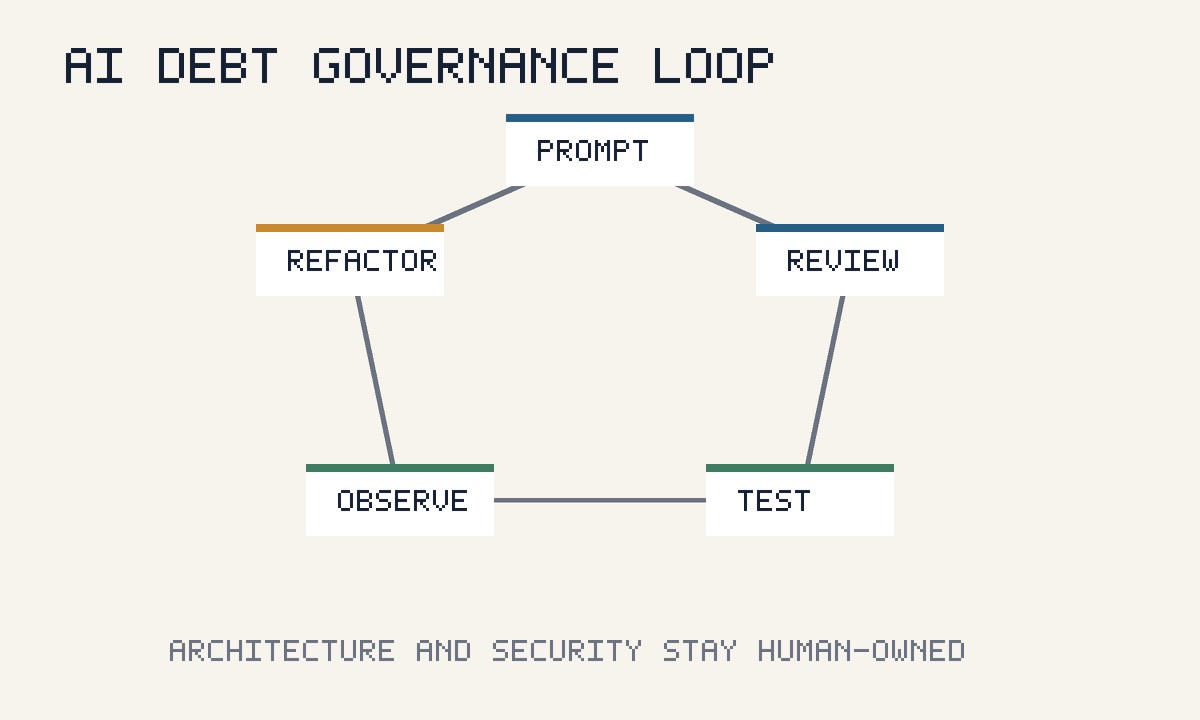
This does not mean teams should avoid AI. It means AI needs engineering controls:
- Treat AI-authored code as draft work, not finished work.
- Require tests for generated logic, especially around edge cases, and use automation testing where repeatability matters.
- Track whether AI-heavy changes have higher bug, rollback, or rework rates.
- Keep architecture decisions human-owned and documented.
- Remove generated duplication quickly instead of letting it settle into the system.
That is part of why the forward deployed engineer model is getting attention in enterprise AI: production deployment depends on integration judgment, not only model access.
Zombie features are product debt, not just code debt
A zombie feature is a feature that still exists in production but no longer creates meaningful customer or revenue value. It may have usage close to zero, no clear owner, stale dependencies, support tickets, and regression test coverage that must be maintained every release.
The problem is not only the direct cost of the feature. The problem is the complexity it adds around everything else. Every abandoned workflow, legacy option, unused integration, and edge-case permission path increases the cost of understanding the system. That complexity slows software risk management and makes every new feature more expensive to design, test, and ship.
Leaders need a “kill switch” habit for features with negative carry. A feature has negative carry when its maintenance, support, QA, security, and infrastructure burden exceeds its business value.
Use a simple rule:
| Feature state | Product signal | Engineering signal | Decision |
|---|---|---|---|
| Growing | Usage and revenue are rising | Tests and ownership are healthy | Keep investing |
| Mature | Usage is stable | Maintenance is predictable | Optimize |
| Declining | Usage is falling | Support and QA cost are rising | Set a review date |
| Zombie | No clear value | Still creates work | Retire, freeze, or replace |
Product teams should not be rewarded only for shipping. They should also be rewarded for removing what no longer deserves to exist.
Run a feature-to-debt audit before the roadmap
A feature-to-debt audit compares where engineering capacity is going against where business value is coming from. It turns technical debt from an emotional debate into an operating review.
Start with four questions:
- What percentage of engineering time went to new capability, maintenance, defects, platform work, security, and support in the last quarter?
- Which modules had the highest code churn, incident rate, and cycle time?
- Which production features have low usage but high maintenance or QA cost?
- Which AI-assisted changes created follow-up fixes, duplicated logic, or unexpected review time?
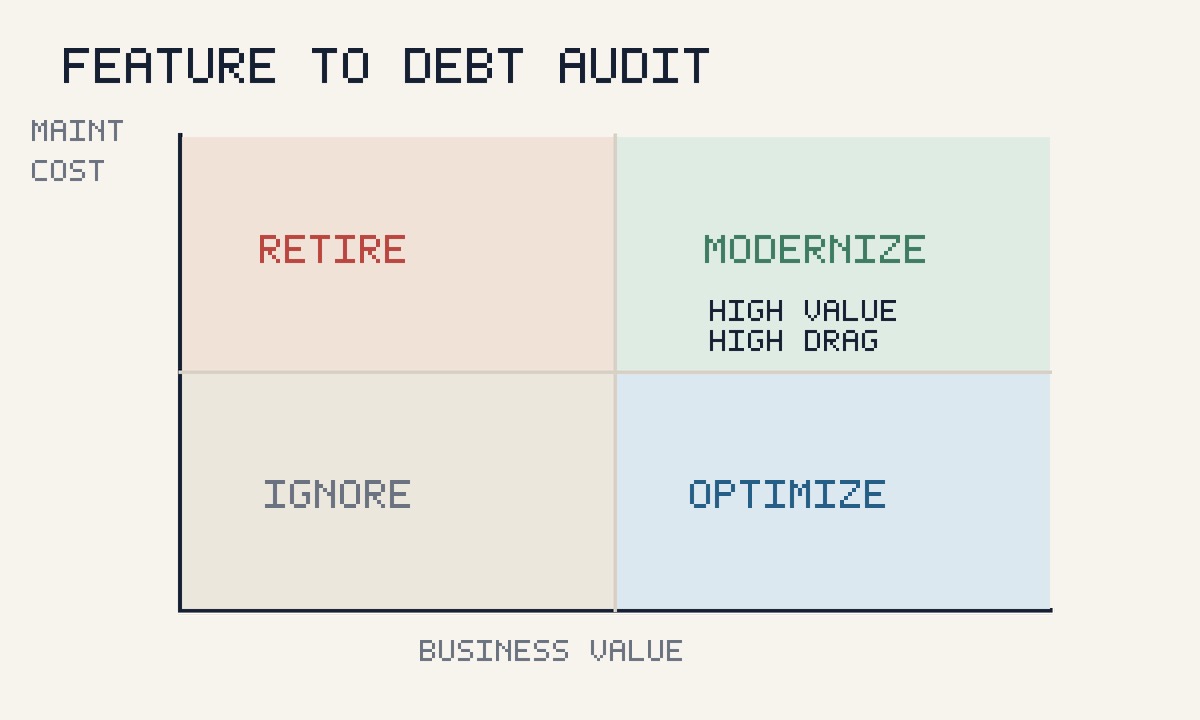
The output should be a ranked list, not a giant refactor wish list. The best debt reduction work usually sits at the intersection of high business value and high maintenance drag. A painful module that blocks revenue deserves attention before a messy corner of the product nobody touches.
For many teams, the audit also exposes a planning mistake: debt is discussed after commitments are made. That is backwards. If a roadmap assumes 100% of engineering capacity is available for new work when 25% to 35% is historically consumed by maintenance, the plan is already fictional.
Shift-left quality is cheaper than late repair
Technical debt compounds when defects are found late. NIST’s work on software errors has long shown that errors become more expensive when they escape the stage where they were introduced. One NIST publication notes that a defect found late in the lifecycle may cost more than one hundred times as much to correct as one found during requirements work.
Modern QA should therefore be treated as debt prevention, not release policing. Strong agile practices make that prevention visible in planning instead of leaving it to late release checks. That means:
- Clear requirements before implementation starts.
- Automated checks in the delivery pipeline.
- Risk-based regression suites instead of bloated test scripts.
- Observability that shows when a release hurts real users.
- Post-incident reviews that fix the system, not just the symptom.
This is also where AI can help safely. AI-generated test ideas, edge-case lists, migration notes, and quality assurance methodology can reduce blind spots. But the quality bar has to live in the pipeline, not in a prompt window.
Modernization should pay down debt in slices
Big-bang rewrites are tempting because they promise a fresh start. They are also dangerous because they ask the business to fund a parallel product before the old system has stopped carrying revenue. In 2026, the safer modernization pattern is incremental replacement.
The Strangler Fig pattern is the most practical example. Microsoft describes it as introducing a facade between the client application, the legacy system, and new services so teams can replace functionality gradually. IBM describes the same modernization logic as taking a monolith apart bit by bit, pulling out the easiest and most valuable parts first until the old system can eventually be retired. See IBM’s overview of application modernization.
For a debt-heavy product, a sensible modernization sequence looks like this:
- Map business value, dependencies, data flows, and incident history.
- Put automated tests and observability around high-risk workflows.
- Expose stable APIs around the legacy system where possible.
- Replace high-churn modules first, not the whole system.
- Retire low-value features before rebuilding them.
- Keep a visible debt ledger tied to cost, risk, and roadmap impact.
The goal is not architectural purity. The goal is to restore engineering solvency: the point where the team can fund new work without constantly borrowing time from future maintenance.
A practical technical debt scorecard for 2026
Use this scorecard in quarterly planning. It is intentionally simple enough for a leadership meeting and concrete enough for engineering to measure.
| Metric | Healthy signal | Warning signal |
|---|---|---|
| Maintenance capacity | Less than 20% of sprint capacity | More than 30% for two quarters |
| Escaped defect rate | Stable or falling after releases | Repeated hotfixes and rollback work |
| Code churn concentration | Churn spread across active modules | Same modules changing every sprint |
| AI-generated rework | AI changes pass normal review and tests | AI-heavy changes create repeated fixes |
| Feature usage | Roadmap tied to active usage | Low-use features still consume QA |
| Modernization ROI | Debt work tied to revenue, risk, or speed | Refactors justified only as cleanup |
This is where technical debt cost in 2026 becomes manageable. You do not need perfect measurement. You need enough visibility to stop pretending every engineering hour has the same strategic value.
FAQ
What is the fastest way to reduce technical debt?
The fastest useful move is a focused audit of the modules that cause the most incidents, churn, and delay. Do not start with a broad rewrite. Start where debt blocks revenue, reliability, or roadmap delivery.
How often should technical debt be measured?
Measure it every sprint at the ticket level and review it every quarter at the business level. Sprint data shows where time is going. Quarterly review shows whether debt is improving, worsening, or merely moving around.
Should technical debt be a board-level metric?
Yes, when the company depends on software for revenue, operations, AI adoption, or customer experience. The board does not need class-level code metrics. It does need capacity loss, modernization risk, incident exposure, and the effect of debt on ROI.
Is refactoring enough?
Refactoring helps, but it is only one tool. Some debt needs better tests, clearer requirements, platform work, feature retirement, security fixes, or incremental modernization. See Hapy’s guide on how to refactor code for the engineering side of the work, and use a clear view of software bug types to decide whether defects point to code cleanup, process gaps, or deeper architecture debt.
The bottom line
Technical debt cost in 2026 is not a vague engineering complaint. It is a measurable business tax on speed, quality, AI ROI, and product focus. The teams that win will not be the teams that write the most code. They will be the teams that know which code still earns its keep, which systems deserve modernization, and which shortcuts are quietly consuming the future.


