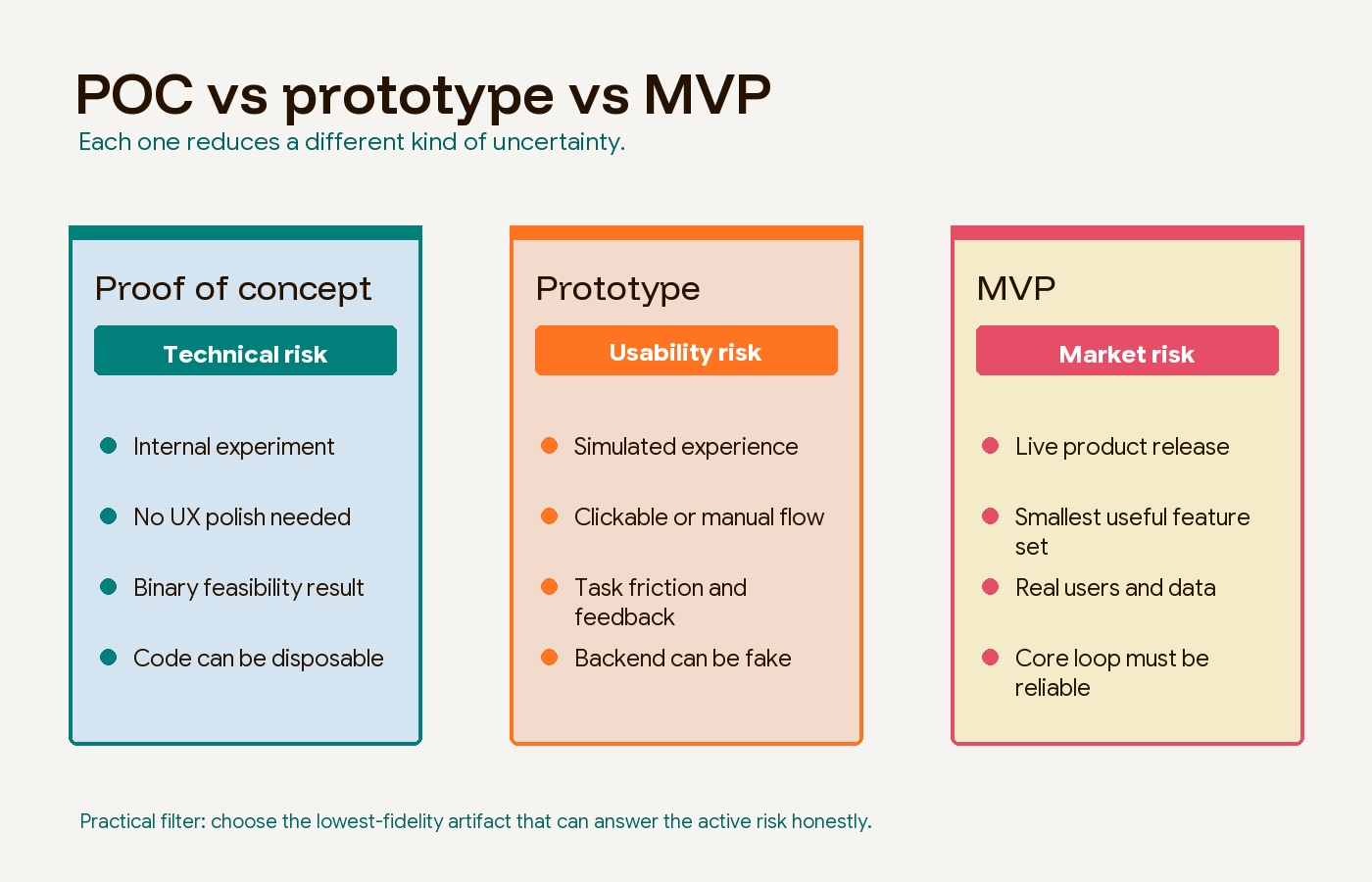
POC vs prototype vs MVP is not a vocabulary debate. It is a budget decision. A proof of concept tests whether a risky idea can work technically. A prototype tests whether people understand the experience. A minimum viable product tests whether real users will adopt, return, or pay.
The mistake is treating all three as interchangeable “early versions.” They are not. Each one reduces a different risk. If you build an MVP when the real question is technical feasibility, you may spend months polishing a product that cannot work. If you build a proof of concept when the real question is customer demand, you may hide inside engineering while the market answer waits outside the building.
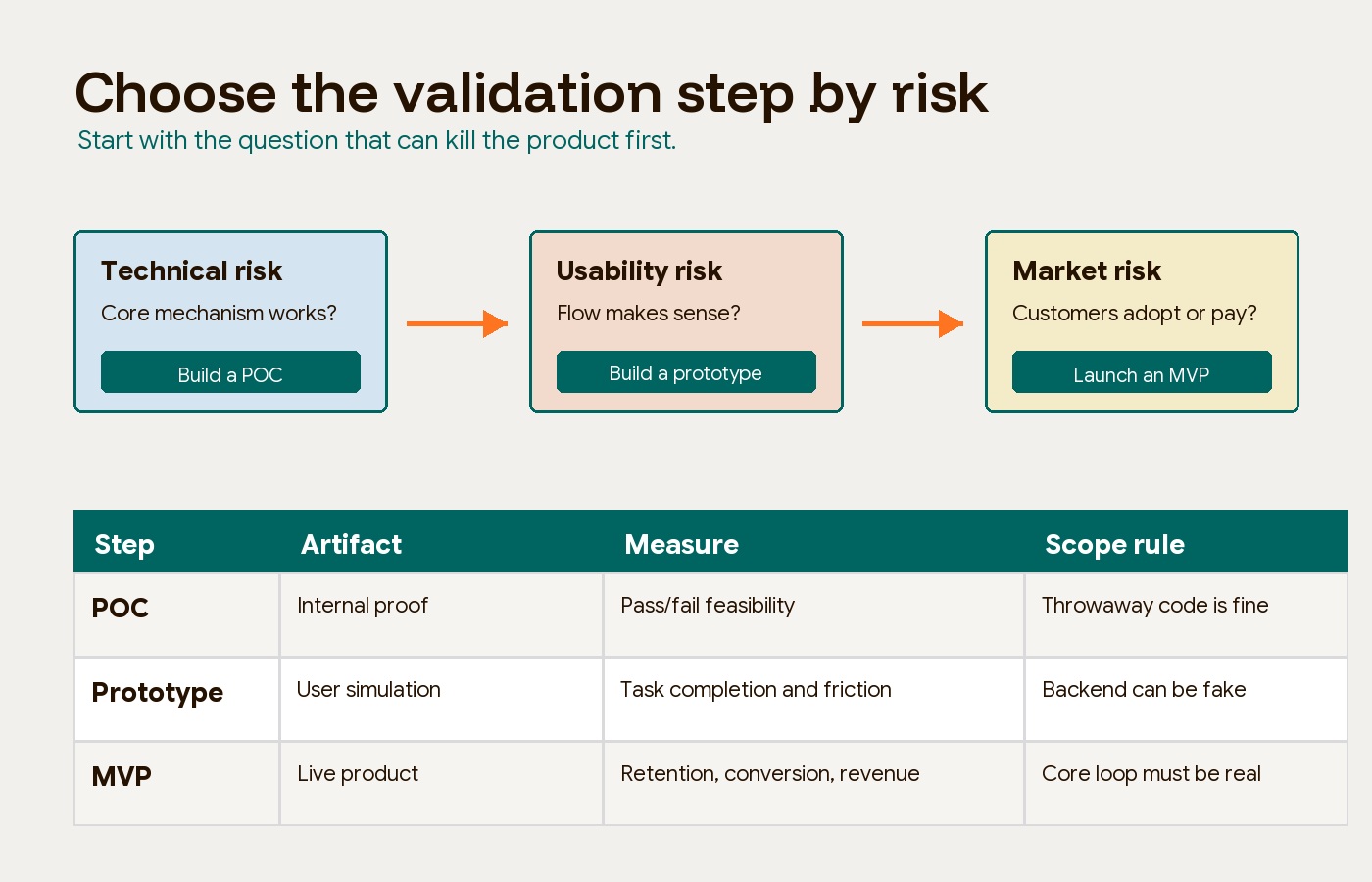
The practical rule is simple: start with the risk that can kill the product first. Technical risk points to a proof of concept. Usability risk points to a prototype. Market risk points to an MVP or an even smaller demand test.
What is the difference between a POC, prototype, and MVP?
A proof of concept, prototype, and MVP are three different validation tools. They sit near each other in early product development, but they answer different questions and should be judged by different success signals.
| Validation step | Core question | Best audience | Output | Success signal |
|---|---|---|---|---|
| Proof of concept | Can this technically work? | Engineers, technical leads, founders | Isolated test, script, integration, model, or hardware experiment | A pass/fail feasibility result |
| Prototype | Can users understand the experience? | Users, stakeholders, investors, design teams | Wireframes, clickable screens, service mockups, or Wizard of Oz flows | Task completion, friction, comprehension, qualitative feedback |
| MVP | Will real users adopt, use, or pay? | Early customers and pilot users | Live product with the smallest useful feature set | Retention, conversion, revenue, activation, repeat usage |
A proof of concept does not need a beautiful interface. It may not need an interface at all. If the risky assumption is “Can we process this data fast enough?” or “Can this AI workflow meet accuracy requirements?”, the proof should be a narrow technical experiment, not a product demo.
A prototype does not need production infrastructure. It needs enough fidelity to reveal whether the user journey makes sense. The Interaction Design Foundation’s guide to prototype fidelity is useful here because it separates rough sketches, storyboards, wireframes, and higher-fidelity prototypes by what they help teams learn.
An MVP is different because it has to operate in the real world. It should be narrow, but it cannot be fake in the way a prototype can be fake. Marty Cagan has warned that teams use “MVP” to mean many different things; his point is worth keeping close: the artifact only matters if it creates valid learning about the product risk in front of you. In Hapy’s own MVP development work, that usually means shaping a small version-one release around one core outcome, then getting it into real conversations with users, investors, or pilot customers.
If version one is already the next step, Hapy’s guide to MVP development challenges covers the scope, analytics, QA, integration, and launch risks founders should settle before the build.
For a more operational pass, use the MVP development checklist to confirm the user, workflow, validation artifact, feature boundary, and post-launch decision rule.
Use a proof of concept when technical feasibility is the biggest risk
Build a proof of concept when the product depends on a technical assumption that could break the whole business. The goal is not to impress users. The goal is to find out, quickly and cheaply, whether the core mechanism works.
Good POC triggers include:
- Unproven AI accuracy, latency, or retrieval quality.
- Real-time sync, location, streaming, or sensor constraints.
- Complex third-party integrations or data migrations.
- Blockchain, hardware, computer vision, medical, fintech, or compliance-heavy workflows.
- Performance requirements that must be proven before product scope matters.
The output should be intentionally constrained. For example, if the product depends on classifying support tickets with AI, the proof of concept should test a representative data set, accuracy thresholds, confidence handling, and failure modes. It should not include onboarding screens, billing, notification preferences, or a dashboard unless those elements are part of the technical risk.
That narrowness is the value. A good POC can save the team from building on top of a weak assumption. The source report included a healthcare example where a GPT-4-based X-ray triage concept failed a bounded technical test before the company spent heavily on portals, booking flows, and clinical operations. That is exactly what a proof of concept is for: discovering the hard no while the cost is still small.
The main trap is letting POC code become the foundation of the product. POC code is often hardcoded, under-tested, and optimized for learning speed rather than resilience. Once feasibility is proven, the production architecture should be designed cleanly instead of stretching the experiment into a real system.
Use a prototype when usability is the biggest risk
Build a prototype when the technology is feasible but the experience is uncertain. A prototype helps answer whether people understand the product, trust the flow, and can complete the core task without confusion.
Prototype risk is common in products with multi-sided workflows, unfamiliar interaction models, dense professional tools, admin-heavy SaaS, onboarding-heavy consumer apps, and AI products where users need to understand what the system did and why.
The right prototype fidelity depends on the question:
| Prototype type | Use it when | Avoid it when |
|---|---|---|
| Paper sketch | You need quick layout and concept feedback | Stakeholders need realistic interaction detail |
| Storyboard | You need to test context, emotion, or service sequence | The main risk is screen-level usability |
| Wireframe | You need to validate structure and navigation | Visual trust or brand perception is central |
| Clickable prototype | You need task-based usability feedback | Backend behavior is the risk |
| Wizard of Oz prototype | You need to simulate automation before building it | Manual operation would distort the experience too much |
| High-fidelity prototype | You need investor, sales, or handoff clarity | Low-fidelity testing would answer the question faster |
Wizard of Oz testing deserves special attention now because AI has made many teams eager to automate too early. In a Wizard of Oz prototype, users interact with what appears to be a working system, while a human operator performs some of the “automated” work behind the scenes. That can be a smart way to test whether users value the outcome before investing in expensive AI logic.
The discipline is to document the hidden manual work. What decisions did the operator make? How long did each step take? Where did judgment matter? What error cases appeared? Those notes become the requirements for the real system. Without that log, the prototype creates a convincing demo but weak engineering guidance.
Use an MVP when market demand is the biggest risk
Build an MVP when the technology and basic user flow are understood, but you still do not know whether customers will use the product in a real setting. The MVP should be the smallest usable version that can create market evidence.
That usually means one user segment, one painful workflow, one core value loop, and enough reliability for real usage. It does not mean every feature in the investor deck. It also does not mean a throwaway prototype with a pricing page attached.
Y Combinator’s guidance on how to plan an MVP is direct: start from the specific user and the smallest product that solves an important problem for them. YC’s essay on shipping early and often pushes the same operating principle: founders learn faster by putting a focused version in front of users than by waiting for a polished launch moment.
For a B2B founder, a strong MVP might be used by three to five pilot customers who speak with the team every week. For a marketplace, it may focus on one city, one niche, or one side of the market first. For an AI workflow product, it may combine automation with human review so the team can measure trust, usefulness, and edge cases before scaling.
The metrics must match the risk:
| MVP risk | Useful signals |
|---|---|
| Demand | Landing page conversion, demo requests, waitlist quality, pilot commitments |
| Activation | Time to first value, setup completion, first successful workflow |
| Retention | Cohort retention, repeat usage, return frequency, churn reasons |
| Willingness to pay | Paid pilots, pricing clicks, upgrade intent, MRR, contract value |
| Unit economics | CAC, payback period, gross margin, support load, LTV/CAC |
Founders often ask how much an MVP should cost. The honest answer is “enough to test the real risk without starving the next iteration.” Hapy’s guide to MVP development cost in 2026 breaks that down by complexity, but the same principle applies at every budget: build the evidence path first.
The decision framework: pick the riskiest unknown first
The best sequence is not always POC, then prototype, then MVP. That sequence is useful only when the product truly carries technical risk, usability risk, and market risk in that order.
Use this triage instead:
| Primary unknown | First validation move | What to ignore for now |
|---|---|---|
| We do not know if the core technology works | Proof of concept | UI polish, onboarding, pricing, scalability beyond the test |
| We do not know if users understand the flow | Prototype | Production backend, edge-case architecture, full feature scope |
| We do not know if users will adopt or pay | MVP or demand test | Secondary features, platform ambitions, future roadmap items |
This is where teams save real money. A standard CRUD SaaS product probably does not need a long technical POC. The risk is usually not whether forms, roles, dashboards, and payments can be built. The risk is whether the target buyer cares enough to switch, pay, or keep using it.
An AI medical workflow, on the other hand, should not start with a polished MVP. The technical and safety risks are too material. A founder should first prove that the model, data, evaluation method, and human review path are good enough to justify product investment.
The same logic applies to hardware. A smart device may start with cheap components, a rough enclosure, and a microcontroller to prove the mechanism. But a production MVP must later solve industrial design, durability, manufacturing, certification, firmware updates, and support. The early proof is not “almost done.” It is evidence that the next investment has a reason to exist.
The industrialization gap: why prototypes are not almost-products
One of the most expensive misunderstandings in early product work is assuming a prototype is close to an MVP. It usually is not.
A prototype may look complete because the screens are polished. But the missing work is structural: database design, authentication, permissions, payments, error handling, monitoring, testing, deployment, security, admin tools, analytics, backup behavior, and support workflows.
That gap is why teams should treat early artifacts honestly:
- POC code is usually disposable.
- Prototype screens are usually disposable or partially reusable as design direction.
- MVP code should be built as the first production foundation, even if the feature set is narrow.
This does not mean an MVP needs enterprise-grade architecture. It means the parts users depend on should be real enough to learn from. If payments, permissions, and data integrity matter to the validation question, they cannot be hand-waved as “later.”
For founders, the budget implication is clear: do not spend all the money getting to a demo. Keep enough budget for the first real release and the first round of learning after launch. The first version will expose the assumptions that documents, workshops, and prototypes miss.
How to scope the first build without losing the lesson
The safest way to scope early product work is to write the learning goal before the feature list. A lightweight product requirements document is enough. It should name the user, the problem, the riskiest assumption, the validation artifact, the success metric, and what is deliberately out of scope.
MoSCoW prioritization is useful here because it forces the team to separate must-have scope from nice-to-have scope. The Agile Business Consortium’s MoSCoW guidance defines the familiar Must, Should, Could, and Won’t categories. For MVP work, the category that matters most is “Won’t.” A clear won’t-have list protects the learning goal from becoming a general product wish list.
Once the first validation step is clear, a product roadmap can turn the learning goal into sequencing, tradeoffs, and release decisions.
Use these questions before authorizing any build:
- What is the single risk we are trying to reduce first?
- Who needs to interact with the artifact for the test to be valid?
- What is the lowest-fidelity version that can answer the question honestly?
- What metric or observation will count as a pass?
- What result would make us stop, pivot, or change the model?
- Which parts are throwaway, and which parts must be production-grade?
If the team cannot answer those questions, it is too early to estimate the build. The next step is product discovery, not a bigger quote.
Examples: how real companies used the right kind of early validation
The famous startup examples are useful only when they are treated as decision patterns, not mythology.
Airbnb’s early test was not a full marketplace. The founders put a basic offer in front of a specific demand moment: conference visitors who needed a place to stay. A Boston University case writeup on Airbnb’s founding story describes the early air mattress rental idea before the company became a scaled platform. The lesson is not “build a landing page.” The lesson is “test the riskiest customer behavior with the smallest credible version.”
Buffer tested interest before building the full product by using a simple site and later a pricing page to measure willingness to pay. Dropbox used a product video to show a complex sync experience before the full technical build was ready. Zappos validated online shoe demand manually before buying inventory at scale.
Those examples differ in format, but the logic is consistent. Each team looked for the cheapest artifact that could produce real evidence. Sometimes that artifact was a landing page. Sometimes it was a video. Sometimes it was a concierge process. Sometimes it was a narrow product in one market.
That is the point founders should copy.
When to skip straight to MVP development
You can skip a formal POC or prototype when the technical path is standard, the user journey is familiar, and the main uncertainty is market behavior.
That is common for many B2B SaaS tools, internal workflow systems, booking products, portals, dashboards, and straightforward marketplace concepts. In those cases, over-investing in prototypes can become a polite way to delay sales conversations.
Skipping ahead does not mean building a bloated MVP. It means shaping the smallest release that can test adoption or payment. For Hapy, that often looks like:
- A focused version-one workflow.
- A narrow user segment.
- A clickable demo only where it helps alignment or sales.
- Production code for the core loop.
- Analytics and feedback paths from day one.
- A deliberate post-launch iteration budget.
If that is the stage you are in, Hapy’s MVP development engagement is designed for founders who have enough conviction to build, but still need version one to earn its future.
FAQ
Is a POC the same as a prototype?
No. A proof of concept tests technical feasibility. A prototype tests the user experience. A POC may be an internal script, model test, integration spike, or hardware experiment. A prototype may be a sketch, wireframe, clickable design, or simulated workflow.
Is a prototype the same as an MVP?
No. A prototype can be simulated and disposable. An MVP is a live product release that real users can use in a real context. A prototype helps the team learn whether the flow makes sense. An MVP helps the team learn whether the market cares.
Should every startup build a POC before an MVP?
No. Build a POC only when technical feasibility is a serious unknown. If the technology is standard and the market risk is higher, a lean MVP or demand test is usually a better use of time and budget.
What comes first: POC, prototype, or MVP?
The riskiest unknown comes first. Start with a POC for technical risk, a prototype for usability risk, and an MVP for market risk. Some products need all three. Some need only one.
How do you know an MVP is good enough to launch?
An MVP is good enough when it can test the core business assumption with real users and without breaking trust. It should include the core workflow, basic reliability, the minimum UX needed for use, and enough measurement to decide whether to continue, change scope, or stop.